May 24, 2021


Blog Post
A Practical Guide to Going Data-Driven
Nicholas Vandrey, Veriff’s Business Intelligence Team Lead, writes his first blog in a series taking a deep dive into how businesses currently use data, and how to make sure you’re doing it right.

It’s no secret that organizations across the globe are eager to harness data. It’s also no secret that most organizations do a very poor job of it. It’s an uphill battle with a multitude of challenges, both technical and operational.
Some of the technical challenges include building a platform that can handle a large number of concurrent queries, developing robust and reliable data pipelines, and wrangling data in a variety of standard and exotic formats.
On the operational side, agreeing on the definition of key metrics, teaching your colleagues to use the tools and data provided by your data team, and establishing data stewardship are some of the first hurdles you’ll need to overcome. In addition, adhering to data privacy regulations such as GDPR without compromising the integrity of your data falls under both categories.
Humble Beginnings
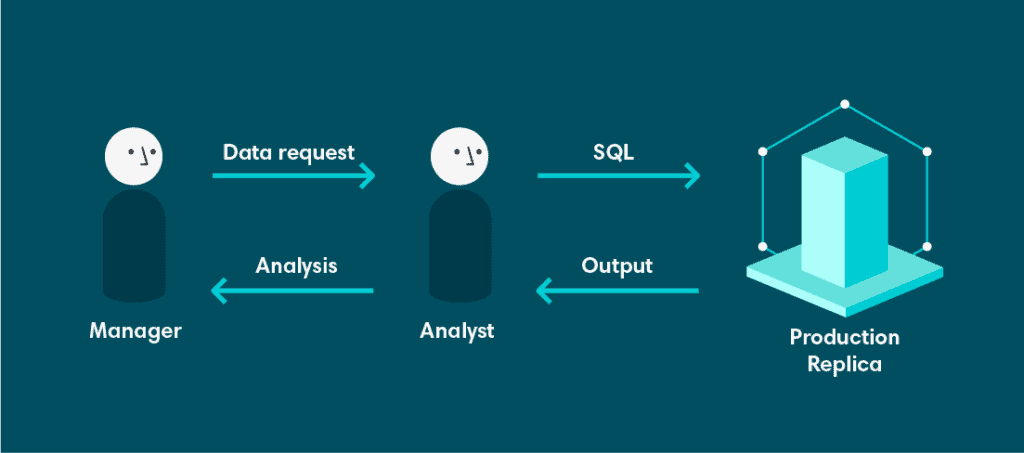
Analytics at Veriff started with a very simple architecture. It started with a database. The database was a read-only replica of our production database. This was suboptimal for several reasons.
Firstly, this database was neither designated nor designed to support complex analytical queries. The data model was highly normalized, because the source database was designed to support Online Transactional Processing (OLTP). This is wonderful if you have a large number of concurrent transactions, all writing or updating a small amount of data, but suffers when trying to read large amounts of data, especially if any processing or aggregating is involved. To make matters worse, this database was shared by all engineers and developers.
Secondly, being a read-only database, we didn’t have the ability to persist results of long-running queries. We also couldn’t set up materialized views on the source database, because long running queries could interrupt availability of our service. Generally, that’s not considered to be desirable.
Finally, we had limited tooling on top of this replica. That means, if you wanted data, you had to get your hands dirty with SQL. While all of our analysts and developers were comfortable with this, the most demand for data came from product owners and managers that weren’t familiar with SQL. This created a hard dependency on analysts, who now had to spend a large amount of time retrieving data and less time extracting value and insights from data.
Things Start to Looker Up
The first issue we wanted to address was the lack of tooling. Analyst time is too scarce to spend on frequent, often repeating, data pulls. If we could provide an interface between the database and the user that allowed them to pull the data themselves, this should allow analysts to focus their efforts elsewhere.
After testing a few tools, we settled on Looker – a tool that provides a semantic layer, an intuitive UI, and an extensive visualization component. The semantic layer allowed us to map objects in our database to corresponding objects in Looker. That way, users could select specific columns from specific tables in a point-and-click manner. On top of that, we could also map arbitrary SQL snippets and queries to Looker dimensions, allowing us to implement pieces of business logic such as metrics definitions in a repeatable, efficient way. Analysts were still responsible for developing and maintaining the semantic layer, but it allowed them to do so in a centralized, version-controlled environment. Once we had mapped our database to Looker, business users were able to start querying data themselves and build their own dashboards.
However, there were still significant issues with this setup. Looker was sitting on top of the same production replica, and all the shortcomings of that database as an analytics source were unchanged. As a matter of fact, it made some of the issues more pronounced. Now, instead of analysts and developers being the only people running heavy queries, anyone with access to Looker was able to do so.
Enter the Data Platform
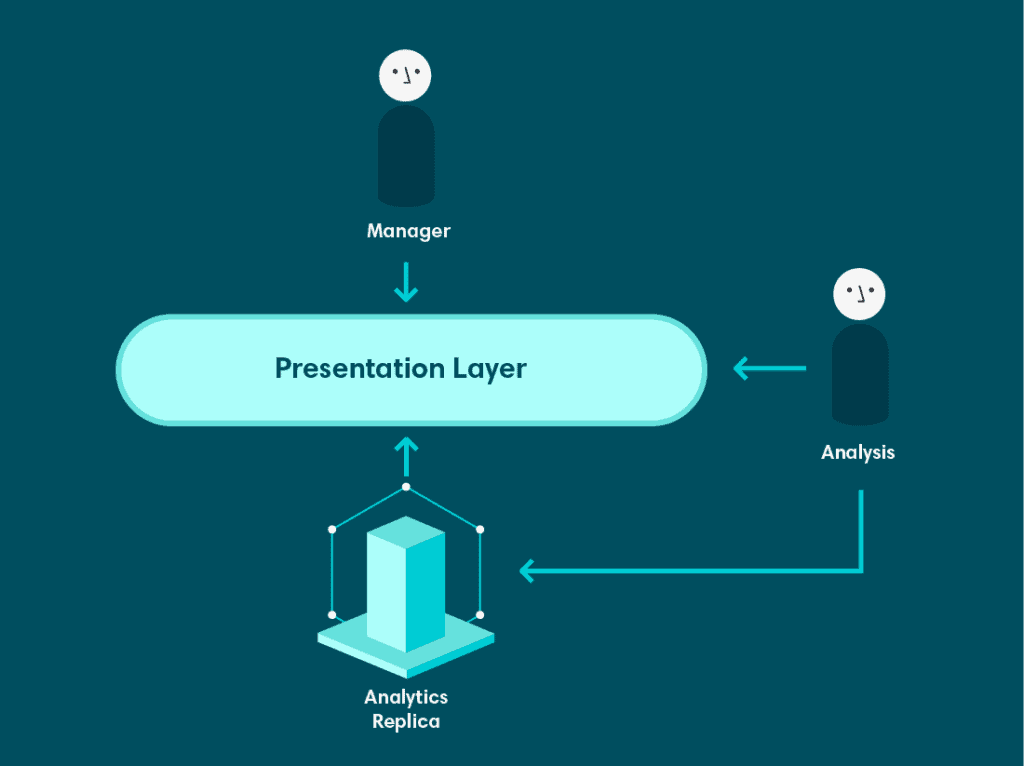
Around the same time we introduced Looker, Veriff had hired a team of experienced database architects. One of the first things they did was set up a more sophisticated replication system to ensure that databases used by production services were isolated from other workloads, and teams that required a replica of the database for a specific function could have one.
As part of this initiative, a replica database was set up specifically for analytics. This was a significant improvement for a few reasons. Principally, it resolved the second issue brought up at the beginning of this post – the inability to persist the results of complex queries. The analytics replica was not a read-only database. We were able to write the output of queries as tables that could then be used further down the line. This both increased the performance of the database, and allowed analysts to build tables that expressed our business logic in a more denormalized fashion rather than relying on the highly normalized data model underneath.
Getting Ready to Scale
The new setup was already a remarkable improvement on our initial setup, but we still needed to take it further. We were still facing a multitude of challenges. Veriff was becoming more data literate, and requests were becoming more complex. This was great, but a lot of the requests required data from sources outside our database, and we didn’t support querying multiple sources from one interface. In addition, data privacy regulations like GDPR meant some data could not be stored in our analytics databases, but we still needed to keep an aggregated overview of our business that guaranteed historical integrity.
We’ll cover how we tackled these challenges, along with some of our plans for the future, in an upcoming blog post. If you’re interested in what you read here, and want to come contribute to it, we’re hiring Data Engineers.