maio 24, 2021


Postagem do Blog
Um Guia Prático para Tornar-se Orientado a Dados
Nicholas Vandrey, Líder da Equipe de Inteligência de Negócios da Veriff, escreve seu primeiro blog em uma série que mergulha fundo em como as empresas atualmente usam dados e como garantir que você está fazendo isso da forma certa.

Não é segredo que organizações em todo o mundo estão ansiosas para aproveitar dados. Também não é segredo que a maioria das organizações faz um trabalho muito ruim nisso. É uma batalha difícil, cheia de desafios, tanto técnicos quanto operacionais
Alguns dos desafios técnicos incluem construir uma plataforma que possa lidar com um grande número de consultas simultâneas, desenvolver pipelines de dados robustos e confiáveis, e manipular dados em uma variedade de formatos padrão e exóticos
Do lado operacional, concordar com a definição de métricas-chave, ensinar seus colegas a usar as ferramentas e os dados fornecidos pela sua equipe de dados e estabelecer a responsabilidade sobre os dados são alguns dos primeiros obstáculos que você precisará superar. Além disso, aderir às regulamentações de privacidade de dados, como o GDPR, sem comprometer a integridade de seus dados, se encaixa em ambas as categorias
Começos Humildes
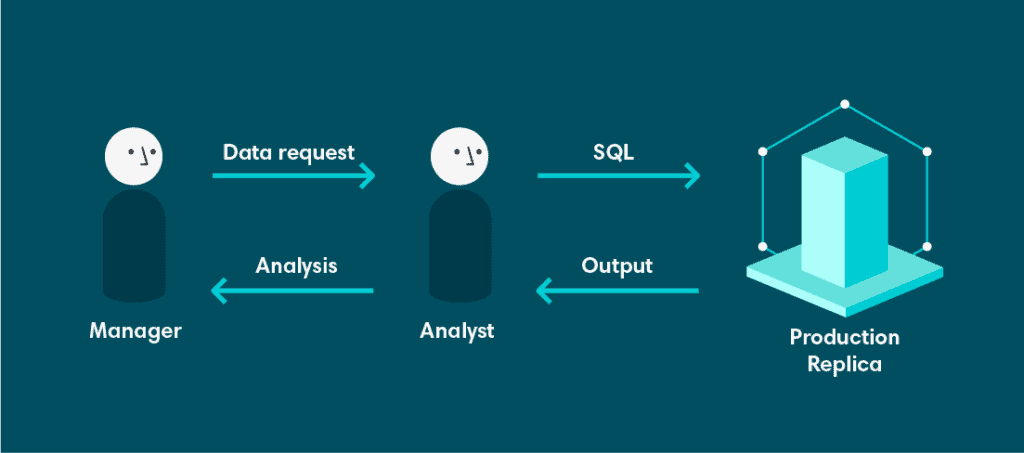
A análise na Veriff começou com uma arquitetura muito simples. Começou com um banco de dados. O banco de dados era uma réplica somente leitura do nosso banco de dados de produção. Isso não era ideal por várias razões.
Em primeiro lugar, esse banco de dados não foi designado nem projetado para suportar consultas analíticas complexas. O modelo de dados era altamente normalizado, porque o banco de dados de origem foi projetado para suportar o Processamento Transacional Online (OLTP). Isso é maravilhoso se você tem um grande número de transações simultâneas, todas escrevendo ou atualizando uma pequena quantidade de dados, mas apresenta dificuldades ao tentar ler grandes quantidades de dados, especialmente se qualquer processamento ou agregação estiver envolvido. Para piorar a situação, esse banco de dados era compartilhado por todos os engenheiros e desenvolvedores
Em segundo lugar, sendo um banco de dados somente leitura, não tínhamos a capacidade de persistir resultados de consultas prolongadas. Também não podíamos configurar visões materializadas no banco de dados de origem, porque consultas longas poderiam interromper a disponibilidade do nosso serviço. Geralmente, isso não é considerado desejável
Finalmente, tínhamos ferramentas limitadas em cima dessa réplica. Isso significa que, se você quisesse dados, teria que se sujar com SQL. Embora todos os nossos analistas e desenvolvedores estivessem confortáveis com isso, a maior demanda por dados vinha de proprietários de produtos e gerentes que não estavam familiarizados com SQL. Isso criou uma dependência forte de analistas, que agora tinham que gastar uma grande quantidade de tempo recuperando dados e menos tempo extraindo valor e insights dos dados.
As Coisas Começam a Melhorar com o Looker
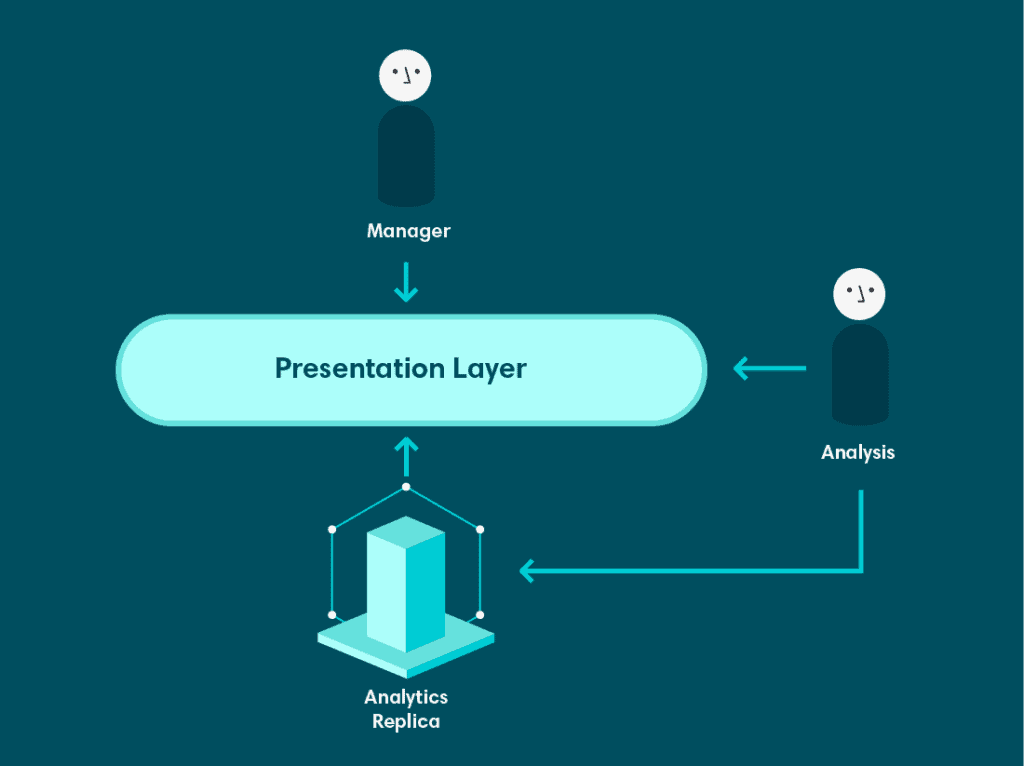
O primeiro problema que queríamos resolver era a falta de ferramentas. O tempo dos analistas é escasso demais para ser desperdiçado em extrações de dados frequentes e repetitivas. Se pudéssemos fornecer uma interface entre o banco de dados e o usuário que permitisse que ele puxasse os dados sozinho, isso deveria permitir que os analistas concentrassem seus esforços em outro lugar.
Após testar algumas ferramentas, escolhemos o Looker – uma ferramenta que fornece uma camada semântica, uma interface intuitiva e um componente de visualização extenso. A camada semântica nos permitiu mapear objetos em nosso banco de dados para objetos correspondentes no Looker. Dessa forma, os usuários podiam selecionar colunas específicas de tabelas específicas de uma maneira simples e intuitiva. Além disso, também podíamos mapear trechos e consultas SQL arbitrárias para dimensões do Looker, permitindo implementar regras de lógica de negócios, como definições de métricas, de maneira repetível e eficiente. Os analistas ainda eram responsáveis por desenvolver e manter a camada semântica, mas isso lhes permitiu fazê-lo em um ambiente centralizado e versionado. Assim que mapeamos nosso banco de dados para o Looker, os usuários de negócios puderam começar a consultar dados por conta própria e construir seus próprios painéis.
No entanto, ainda havia problemas significativos com essa configuração. O Looker estava em cima da mesma réplica de produção e todas as deficiências daquele banco de dados como fonte de análise permaneceram inalteradas. Na verdade, isso acentuou alguns dos problemas. Agora, em vez de analistas e desenvolvedores serem as únicas pessoas executando consultas pesadas, qualquer um com acesso ao Looker podia fazê-lo.
A Plataforma de Dados Entra em Cena
Na mesma época em que introduzimos o Looker, a Veriff contratou uma equipe de arquitetos de banco de dados experientes. Uma das primeiras coisas que fizeram foi configurar um sistema de replicação mais sofisticado para garantir que os bancos de dados usados pelos serviços de produção estivessem isolados de outras cargas de trabalho e equipes que precisassem de uma réplica do banco de dados para uma função específica pudessem ter uma
Como parte dessa iniciativa, um banco de dados de réplica foi configurado especificamente para análise. Isso foi uma melhoria significativa por algumas razões. Principalmente, resolveu o segundo problema levantado no início deste post – a incapacidade de persistir os resultados de consultas complexas. A réplica de análise não era um banco de dados somente leitura. Conseguimos escrever a saída de consultas como tabelas que poderiam ser usadas posteriormente. Isso aumentou tanto o desempenho do banco de dados quanto permitiu que os analistas construíssem tabelas que expressassem nossa lógica de negócios de uma forma mais desnormalizada, em vez de depender do modelo de dados altamente normalizado por baixo.
Preparando-se para Escalar
A nova configuração já era uma melhoria notável em relação à nossa configuração inicial, mas ainda precisávamos avançar. Continuávamos enfrentando uma infinidade de desafios. A Veriff estava se tornando mais alfabetizada em dados, e os pedidos estavam se tornando mais complexos. Isso era ótimo, mas muitos dos pedidos requeriam dados de fontes externas ao nosso banco de dados, e não suportávamos consultas de múltiplas fontes a partir de uma única interface. Além disso, regulamentações de privacidade de dados como o GDPR significavam que alguns dados não podiam ser armazenados em nossos bancos de dados de análise, mas ainda precisávamos manter uma visão agregada do nosso negócio que garantisse a integridade histórica.
Cobraremos como enfrentamos esses desafios, juntamente com alguns de nossos planos para o futuro, em um próximo post no blog. Se você se interessou pelo que leu aqui e quer contribuir, estamos contratando Engenheiros de Dados.