mayo 24, 2021


Entrada de blog
Una Guía Práctica para Volverse Orientado a Datos
Nicholas Vandrey, líder del equipo de Inteligencia de Negocios de Veriff, escribe su primer blog en una serie en la que se profundiza en cómo las empresas utilizan actualmente los datos y cómo asegurarte de que lo estás haciendo de la manera correcta.

No es un secreto que las organizaciones de todo el mundo están ansiosas por aprovechar los datos. Tampoco es un secreto que la mayoría de las organizaciones lo hacen muy mal. Es una batalla cuesta arriba con una multitud de desafíos, tanto técnicos como operativos.
Algunos de los desafíos técnicos incluyen la construcción de una plataforma que pueda manejar un gran número de consultas concurrentes, el desarrollo de tuberías de datos robustas y confiables, y el manejo de datos en una variedad de formatos estándar y exóticos.
Desde el lado operativo, llegar a un acuerdo sobre la definición de métricas clave, enseñar a tus compañeros a usar las herramientas y los datos proporcionados por tu equipo de datos, y establecer la gestión de datos son algunos de los primeros obstáculos que necesitarás superar. Además, cumplir con regulaciones de privacidad de datos como el GDPR sin comprometer la integridad de tus datos se incluye en ambas categorías.
Comienzos Humildes
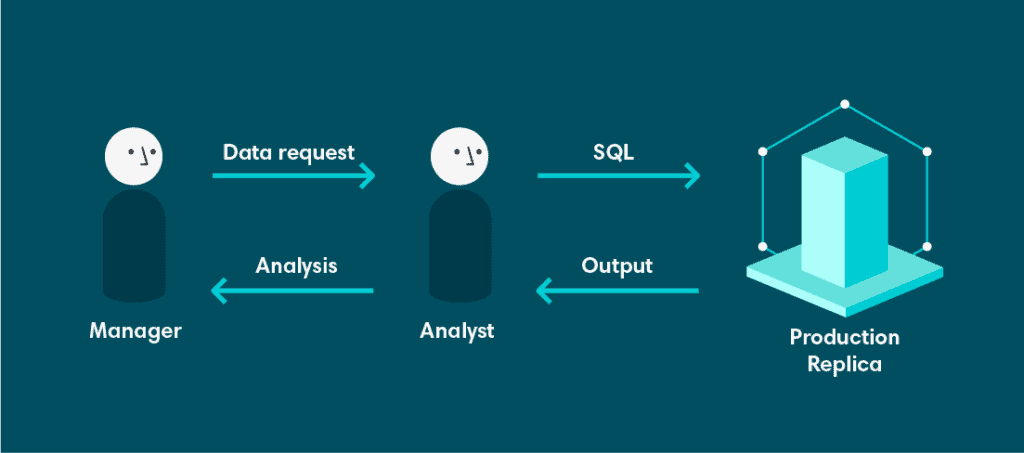
La analítica en Veriff comenzó con una arquitectura muy simple. Comenzó con una base de datos. La base de datos era una réplica de solo lectura de nuestra base de datos de producción. Esto era subóptimo por varias razones.
En primer lugar, esta base de datos no estaba designada ni diseñada para soportar consultas analíticas complejas. El modelo de datos estaba altamente normalizado, porque la base de datos de origen estaba diseñada para soportar Procesamiento Transaccional en Línea (OLTP). Esto es maravilloso si tienes un gran número de transacciones concurrentes, todas escribiendo o actualizando una pequeña cantidad de datos, pero sufre al intentar leer grandes cantidades de datos, especialmente si se involucra algún procesamiento o agregación. Para empeorar las cosas, esta base de datos era compartida por todos los ingenieros y desarrolladores.
En segundo lugar, al ser una base de datos de solo lectura, no teníamos la capacidad de persistir resultados de consultas de larga duración. Tampoco pudimos configurar vistas materializadas en la base de datos de origen, porque las consultas de larga duración podrían interrumpir la disponibilidad de nuestro servicio. Generalmente, eso no se considera deseable.
Finalmente, teníamos herramientas limitadas sobre esta réplica. Eso significa que, si querías datos, tenías que ensuciarte las manos con SQL. Si bien todos nuestros analistas y desarrolladores se sentían cómodos con esto, la mayor demanda de datos provenía de propietarios de productos y gerentes que no estaban familiarizados con SQL. Esto creó una fuerte dependencia de los analistas, quienes ahora debían dedicar gran parte de su tiempo a recuperar datos y menos tiempo extrayendo valor y conocimientos de los mismos.
Las cosas comienzan a mejorar gracias a Looker
El primer problema que queríamos abordar era la falta de herramientas. El tiempo de los analistas es demasiado escaso para gastarlo en extracciones de datos frecuentes y a menudo repetitivas. Si pudiéramos proporcionar una interfaz entre la base de datos y el usuario que les permitiera extraer los datos por sí mismos, esto debería permitir a los analistas concentrar sus esfuerzos en otros lugares.
Después de probar algunas herramientas, nos decidimos por Looker, una herramienta que proporciona una capa semántica, una interfaz intuitiva y un componente de visualización extenso. La capa semántica nos permitió mapear objetos en nuestra base de datos a objetos correspondientes en Looker. De esa manera, los usuarios podían seleccionar columnas específicas de tablas específicas de manera sencilla. Además, también pudimos mapear fragmentos de SQL arbitrarios y consultas a dimensiones de Looker, lo que nos permitió implementar piezas de lógica empresarial como definiciones de métricas de manera repetible y eficiente. Los analistas seguían siendo responsables de desarrollar y mantener la capa semántica, pero les permitió hacerlo en un entorno centralizado y controlado por versiones. Una vez que mapeamos nuestra base de datos a Looker, los usuarios de negocios pudieron comenzar a consultar datos por sí mismos y construir sus propios paneles.
Sin embargo, aún había problemas significativos con esta configuración. Looker estaba sobre la misma réplica de producción, y todas las deficiencias de esa base de datos como fuente de análisis permanecían sin cambios. De hecho, algunos problemas se hicieron más pronunciados. Ahora, en lugar de que solo los analistas y desarrolladores fueran las únicas personas que realizaban consultas complejas, cualquiera con acceso a Looker podía hacerlo.
Entra la Plataforma de Datos
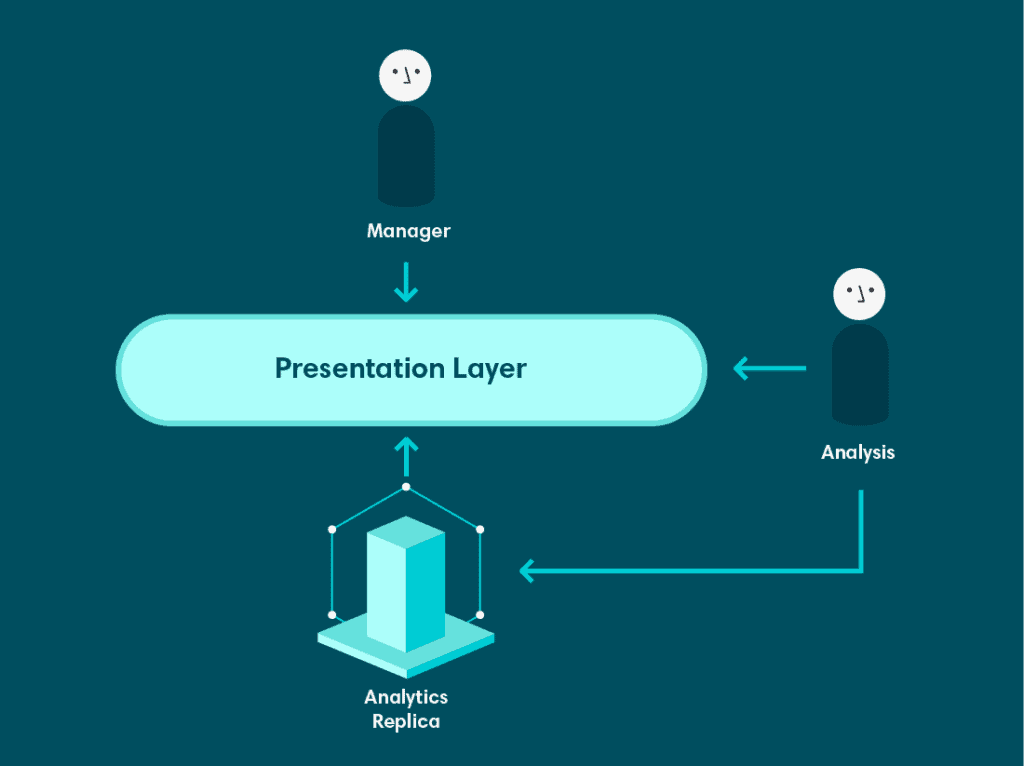
Al mismo tiempo que introdujimos Looker, Veriff había contratado un equipo de arquitectos de bases de datos experimentados. Una de las primeras cosas que hicieron fue establecer un sistema de replicación más sofisticado para garantizar que las bases de datos utilizadas por los servicios de producción estuvieran aisladas de otras cargas de trabajo, y los equipos que requerían una réplica de la base de datos para una función específica pudieran tener una.
Como parte de esta iniciativa, se configuró una base de datos réplica específicamente para analítica. Esta fue una mejora significativa por varias razones. Principalmente, resolvió el segundo problema planteado al principio de esta publicación: la incapacidad de persistir los resultados de consultas complejas. La réplica de analítica no era una base de datos de solo lectura. Pudimos escribir la salida de las consultas como tablas que luego podrían ser utilizadas más adelante. Esto aumentó tanto el rendimiento de la base de datos como permitió a los analistas construir tablas que expresaban nuestra lógica empresarial de una manera más desnormalizada en lugar de depender del altamente normalizado modelo de datos subyacente.
Preparándonos para Escalar
La nueva configuración ya era una mejora notable sobre nuestra configuración inicial, pero aún necesitábamos llevarlo más allá. Aún enfrentábamos una multitud de desafíos. Veriff se estaba volviendo más alfabetizada en datos, y las solicitudes se volvían más complejas. Esto era genial, pero muchas de las solicitudes requerían datos de fuentes externas a nuestra base de datos, y no apoyamos la consulta de múltiples fuentes desde una única interfaz. Además, las regulaciones de privacidad de datos como el GDPR significaban que algunos datos no podían ser almacenados en nuestras bases de datos analíticas, pero aún necesitábamos mantener una visión agregada de nuestro negocio que garantizara la integridad histórica.
Abordaremos cómo enfrentamos estos desafíos, junto con algunos de nuestros planes para el futuro, en una próxima publicación de blog. Si te interesa lo que leíste aquí y quieres contribuir, estamos contratando Ingenieros de Datos.