mayo 24, 2021


Entrada de blog
Cómo Veriff Comparte GPUs – Una guía técnica
Siim Tiilen, un Ingeniero de Calidad en nuestro equipo de DevOps, explica prácticamente cómo Veriff comparte GPUs entre pods y cómo nos ha ayudado a reducir nuestro costo total de infraestructura.

Debido a la creciente importancia de la IA en nuestra pila, estamos utilizando extensivamente unidades de procesamiento gráfico (GPUs) en Kubernetes para ejecutar diversas cargas de trabajo de aprendizaje automático (ML). En este blog, describiré cómo hemos estado compartiendo GPUs entre pods durante los últimos 2 años para reducir drásticamente nuestro costo de infraestructura.
Ejemplo de uso de GPU NVIDIA
Al utilizar GPU de NVIDIA, necesita usar el plugin de dispositivo NVIDIA para Kubernetes que declara un nuevo recurso personalizado, nvidia.com/gpu, que puede usar para asignar GPUs a los pods de Kubernetes. El problema con este enfoque es que no puede dividirlos entre múltiples aplicaciones (PODs) y las GPU son un recurso muy costoso.
```yaml apiVersion: v1 kind: Pod metadata: name: gpu-example spec: restartPolicy: OnFailure containers: - name: gpu-example image: eritikass/gpu-load-test imagePullPolicy: Always recursos: limits: nvidia.com/gpu: 1 ```
¿Qué sucede cuando despliegas una GPU usando aplicaciones como esta? Kubernetes está usando el recurso nvidia.com/gpu para desplegar este pod en un nodo donde hay una GPU disponible.
Si te conectas (ssh) al nodo donde este pod está corriendo, y usas el comando nvidia-smi allí, puedes obtener un resultado similar a este.
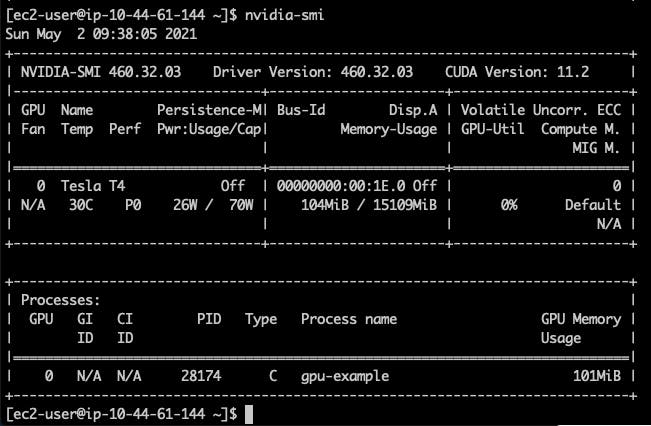
La información visible aquí es que nuestro nodo tiene 1 NVIDIA Tesla T4 GPU con 15109MiB de memoria y estamos utilizando 104MiB de eso con un proceso (nuestro pod desplegado).
Internamente hay una variable muy importante que se le da a cada pod y la aplicación la está utilizando para saber qué GPUs usar.

# conectar al pod kubectl exec -it pod/gpu-example -- bash #y comprobar echo $NVIDIA_VISIBLE_DEVICES
En el ejemplo anterior, esta GPU – GPU-93955ff6-1bbe-3f6d-8d58-a2104edb62db – está siendo utilizada por la aplicación. Cuando tienes un nodo con múltiples GPUs, en realidad todos los pods pueden acceder a todas las GPUs, pero todas están usando esta variable para saber a qué GPU deben acceder.
Esta variable también tiene un valor «mágico»: all. Usando esto puedes anular la asignación de GPU y dejar que tu aplicación sepa que puede usar cualquier (todas) las GPUs presentes en tu nodo.
Compartiendo GPU MVP
Sabemos que nuestra aplicación de ejemplo está usando 104MiB y la GPU tiene un total de 15109MiB, por lo que en teoría podemos ajustarla 145 veces en la misma GPU.
En el siguiente ejemplo, necesitará tener un clúster AWS EKS con 1 instancia de GPU (g4dn.xlarge), y con algunas modificaciones debería ser posible usarlo en cualquier clúster de Kubernetes con nodos de GPU Nvidia disponibles.
```yaml apiVersion: apps/v1 kind: Deployment metadata: name: gpu-example spec: # En este ejemplo, ejecutaremos 5 pods con fines de demostración. # # NB: los nodos aws g4 pueden ejecutar un máximo de 29 pods debido a límites de red, # https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI replicas: 5 selector: matchLabels: app: gpu-example template: metadata: labels: app: gpu-example spec: # Usaremos afinidad para asegurarnos de que el pod (o pods) en este despliegue # solo se asigne a nodos que estén utilizando la instancia g4dn.xlarge. # De este modo, podemos estar seguros de que hay GPU disponible. affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node.kubernetes.io/instance-type operator: In values: - g4dn.xlarge containers: - name: gpu-example image: eritikass/gpu-load-test env: # esto permitirá a las aplicaciones cuda saber que deben usar cualquier GPU disponible - name: NVIDIA_VISIBLE_DEVICES value: all ```
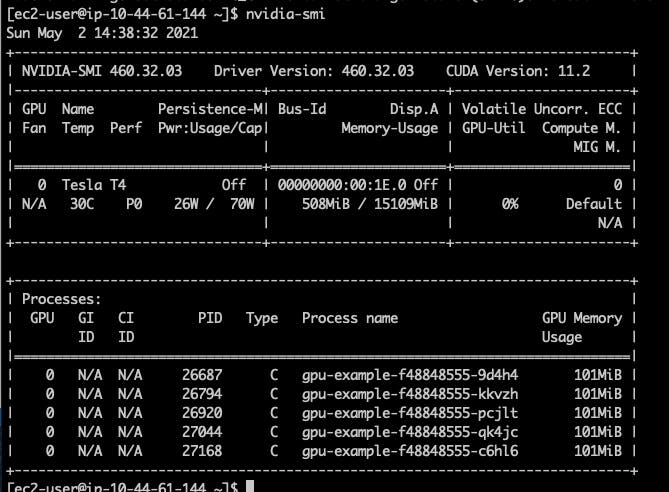
Si verificamos después de eso, podemos ver que los 5 pods están asignados al mismo nodo.

Y cuando verificamos nvidia-smi en este nodo, podemos ver que hay 5 procesos GPU en ejecución de esos pods.
Usando recursos personalizados
Ahora que sabemos que múltiples pods que usan GPU pueden ejecutarse en el mismo nodo, necesitamos asegurarnos de que estén divididos entre nodos según la capacidad del nodo para manejar los requisitos del pod. Para esto, podemos usar Recursos Personalizados para permitir que todos los nodos GPU sepan que tienen tanta memoria GPU disponible para usar.
Usaremos DaemonSet para agregar recurso de memoria GPU personalizado (lo llamamos veriff.com/gpu-memory) para agregar nodos con una GPU NVIDIA adjunta. DaemonSet es un tipo especial de despliegue de Kubernetes que ejecutará 1 pod en algunos (o todos) nodos del clúster, se usa bastante para desplegar cosas como recolectores de registros y herramientas de monitoreo. Nuestro DaemonSet tendrá afinidad del nodo para asegurarse de que solo se ejecute en nodos g4dn.xlarge.
```yaml
---
#
# mapas de configuración que contienen el script que se ejecuta inside daemset en todos los nodos gpu para establecer memoria gpu
#
apiVersion: v1
kind: ConfigMap
metadata:
name: add-gpu-memory
namespace: kube-system
datos:
app.sh: |
#!/bin/bash
gpu_memory_value="15079Mi"
timeout 240 kubectl proxy &
sleep 3
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--max-time 10 --retry 10 --retry-delay 2 \
--data "[{\"op\": \"add\", \"path\": \"/status/capacity/veriff.com~1gpu-memory\", \"value\": \"${gpu_memory_value}\"}]" \
"http://127.0.0.1:8001/api/v1/nodes/${K8S_NODE_NAME}/status"
echo " * ${gpu_memory_value} de memoria gpu añadido a ${K8S_NODE_NAME} (veriff.com/gpu-memory)"
sleep infinity
---
#
# este DaemonSet se ejecutará en todos los nodos g4dn.xlarge y los parchará para agregarles recursos personalizados de memoria gpu
#
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: add-gpu-memory
namespace: kube-system
spec:
selector:
matchLabels:
name: add-gpu-memory
template:
metadata:
labels:
name: add-gpu-memory
spec:
tolerations:
- key: "special"
operator: "Exists"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- g4dn.xlarge
serviceAccountName: add-gpu-memory
containers:
- name: add-gpu-memory
image: bitnami/kubectl
recursos:
limits:
cpu: 40m
memory: 50M
requests:
cpu: 1m
memory: 1M
volumeMounts:
- mountPath: /app.sh
name: code
readOnly: true
subPath: app.sh
command:
- bash
- /app.sh
env:
#
# esta variable se usa en el script para organizar nodos y saber en qué nodo está corriendo
#
- name: "K8S_NODE_NAME"
valueFrom:
fieldRef:
apiVersion: "v1"
fieldPath: "spec.nodeName"
priorityClassName: system-node-critical
volumes:
- name: code
configMap:
name: add-gpu-memory
#
# permisos de rbac utilizados por daemonset para parchear nodos
#
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: add-gpu-memory
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: add-gpu-memory
namespace: kube-system
reglas:
- gruposApi:
- "*"
recursos:
- nodos
verbos:
- obtener
- listar
- gruposApi:
- "*"
recursos:
- nodos/estado
verbos:
- parchear
---
apiVersion: rbac.authorization.k8s.io/v1
tipo: ClusterRoleBinding
metadata:
name: add-gpu-memory
namespace: kube-system
rolRef:
grupoApi: rbac.authorization.k8s.io
kind: ClusterRole
name: add-gpu-memory
sujetos:
- tipo: CuentaDeServicio
name: add-gpu-memory
namespace: kube-system
```
Si verificas tu nodo usando “kubectl describe node/NAME” puedes ver que tiene el recurso veriff.com/gpu-memory disponible.
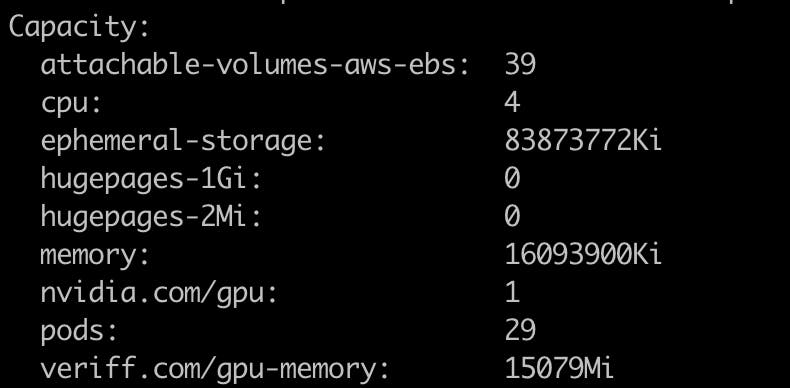
Ahora que sabemos que nuestro script para agregar memoria GPU funciona, escalemos nuestro clúster para que tengamos múltiples nodos GPU disponibles.
Para probarlo, modificaremos nuestro despliegue para usar este nuevo recurso.
```yaml apiVersion: apps/v1 kind: Deployment metadata: name: gpu-example spec: réplicas: 6 selector: matchLabels: app: gpu-example template: metadata: labels: app: gpu-example spec: containers: - name: gpu-example image: eritikass/gpu-load-test env: # esto permitirá a las aplicaciones cuda saber que deben usar cualquier GPU disponible - name: NVIDIA_VISIBLE_DEVICES value: all recursos: requests: veriff.com/gpu-memory: 104Mi limits: veriff.com/gpu-memory: 104Mi ```
Después de eso, es visible que los pods están distribuidos entre nodos.

Con recursos regulares como CPU y memoria, Kubernetes sabrá cuánto están usando realmente los pods (contenedores) y si alguien intenta usar más – Kubernetes lo restringirá. Sin embargo, con nuestro nuevo recurso personalizado, no hay ninguna salvaguarda real en su lugar que impida que algún pod “malévolo” no tome más memoria GPU de la declarada. Por lo tanto, debes tener mucho cuidado al establecer los recursos allí. Cuando los pods intentan usar más memoria GPU de la que hay disponible en un nodo, normalmente resulta en algunos accidentes muy feos.
En Veriff, resolvimos este problema con un monitoreo y alertas extensivas para nuestro nuevo uso de Recursos Personalizados de GPU. También hemos desarrollado herramientas internamente para medir el uso de GPU en aplicaciones de ML bajo carga.
Todos los ejemplos de código de esta publicación se pueden encontrar en https://github.com/Veriff/gpu-sharing-examples.