maio 24, 2021


Postagem do Blog
Como a Veriff compartilha GPUs – Um guia técnico
Siim Tiilen, um Engenheiro de Qualidade em nossa equipe de DevOps, explica de forma prática como a Veriff compartilha GPUs entre pods e como isso nos ajudou a reduzir nosso custo geral de infraestrutura.

Devido à crescente importância da IA em nossa pilha, estamos usando extensivamente unidades de processamento gráfico (GPUs) no Kubernetes para executar várias cargas de trabalho de aprendizado de máquina (ML). Neste blog, vou descrever como temos compartilhado GPUs entre pods nos últimos 2 anos para reduzir drasticamente nossos custos de infraestrutura.
Exemplo de uso de GPU NVIDIA
Ao usar as GPUs da NVIDIA, você precisa usar o plugin de dispositivo NVIDIA para Kubernetes que declara um novo recurso personalizado, nvidia.com/gpu, que você pode usar para atribuir GPUs aos pods do Kubernetes. O problema com essa abordagem é que você não pode dividi-las entre várias aplicações (PODs) e as GPUs são um recurso muito caro.
```yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-example
spec:
restartPolicy: OnFailure
containers:
- name: gpu-example
image: eritikass/gpu-load-test
imagePullPolicy: Always
resources:
limits:
nvidia.com/gpu: 1
```
Então, o que acontece quando você implanta uma GPU usando aplicativos assim? Kubernetes está usando o recurso nvidia.com/gpu para implantar este pod em um nó onde uma GPU está disponível.
Se você se conectar (ssh) no nó onde este pod está em execução e usar o comando nvidia-smi lá, você pode obter um resultado semelhante a este.
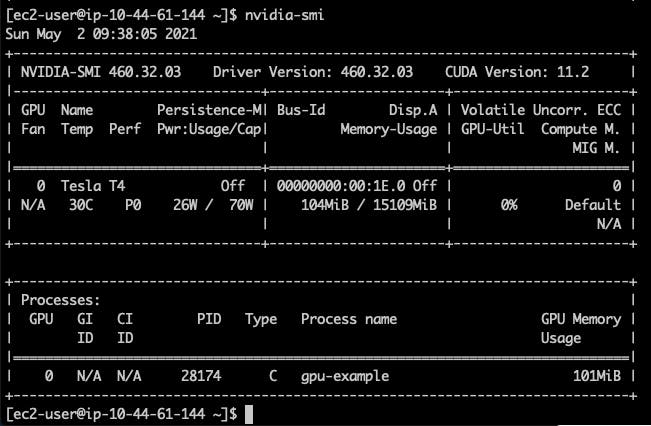
A informação visível aqui é que nosso nó tem 1 NVIDIA Tesla T4 GPU com 15109MiB de memória e estamos usando 104MiB disso com um processo (nosso pod implantado).
Internamente, há uma variável muito importante que é dada a cada pod e a aplicação está usando isso para saber quais GPUs usar.

# connect to pod kubectl exec -it pod/gpu-example -- bash #and check echo $NVIDIA_VISIBLE_DEVICES
No exemplo acima, esta GPU – GPU-93955ff6-1bbe-3f6d-8d58-a2104edb62db – está sendo usada pela aplicação. Quando você tem um nó com várias GPUs, na verdade todos os pods podem acessar todas as GPUs – mas todos estão usando esta variável para saber qual GPU eles devem acessar.
Esta variável também tem um valor “mágico”: all. Usando isso, você pode substituir a alocação de GPUs e informar à sua aplicação que pode usar qualquer (todas) GPUs presentes em seu nó.
Compartilhamento de GPU MVP
Sabemos que nossa aplicação de exemplo está usando 104MiB e a GPU tem um total de 15109MiB, então, em teoria, podemos encaixá-la 145 vezes na mesma GPU.
No próximo exemplo você precisa ter um cluster AWS EKS com 1 instância de GPU (g4dn.xlarge), e com algumas modificações deve ser possível usá-lo em qualquer cluster Kubernetes com nós de GPU Nvidia disponíveis.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-example
spec:
# Neste exemplo, vamos executar 5 pods para fins de demonstração.
#
# NB: nós g4 da AWS podem executar no máximo 29 pods devido a limitações de rede,
# https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI
replicas: 5
selector:
matchLabels:
app: gpu-example
template:
metadata:
labels:
app: gpu-example
spec:
# Vamos usar afinidade para garantir que pod(s) deste deployment
# só podem ser atribuídos a nós que estão usando a instância g4dn.xlarge.
# Dessa forma, podemos ter certeza de que há uma GPU disponível.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- g4dn.xlarge
containers:
- name: gpu-example
image: eritikass/gpu-load-test
env:
# isso fará com que a aplicação cuda saiba usar qualquer GPU disponível
- name: NVIDIA_VISIBLE_DEVICES
value: all
```
```
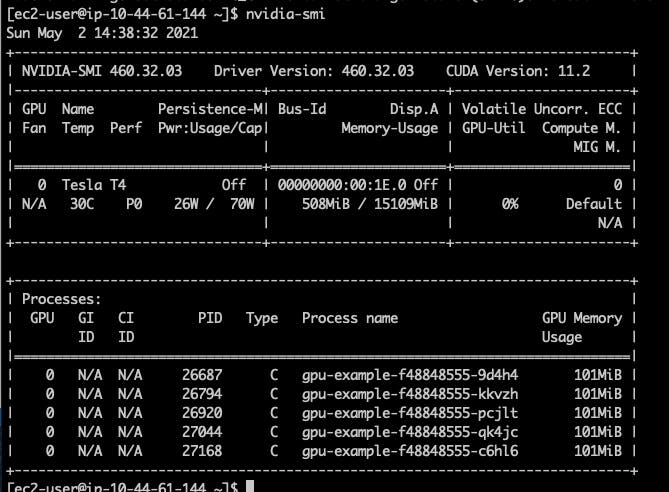
Se verificarmos depois disso, podemos ver que todos os 5 pods estão atribuídos ao mesmo nó.

E quando verificamos nvidia-smi neste nó, podemos ver que há 5 processos de GPU em execução desses pods.
Usando recursos personalizados
Agora que sabemos que múltiplos pods que utilizam GPU podem correr no mesmo nó, precisamos garantir que sejam distribuídos entre os nós com base na capacidade do nó para atender aos requisitos do pod. Para isso, podemos usar Recursos Personalizados para informar a todos os nós de GPU que eles têm tanta memória GPU disponível para uso.
Usaremos DaemonSet para adicionar um recurso de memória GPU personalizado (nomeamos como veriff.com/gpu-memory) para adicionar nós com uma GPU NVIDIA conectada. O DaemonSet é um tipo especial de implantação do Kubernetes que executará 1 pod em alguns (ou todos) os nós do cluster, frequentemente é usado para implantar coisas como coletores de logs e ferramentas de monitoramento. Nosso DaemonSet terá afinidade de nó para garantir que ele só será executado em nós g4dn.xlarge.
```yaml
---
#
# config maps that is holding the script that is run inside DaemonSet in all gpu nodes to set gpu memory
#
apiVersion: v1
kind: ConfigMap
metadata:
name: add-gpu-memory
namespace: kube-system
data:
app.sh: |
#!/bin/bash
gpu_memory_value="15079Mi"
timeout 240 kubectl proxy &
sleep 3
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--max-time 10 --retry 10 --retry-delay 2 \
--data "[{\"op\": \"add\", \"path\": \"/status/capacity/veriff.com~1gpu-memory\", \"value\": \"${gpu_memory_value}\"}]" \
"http://127.0.0.1:8001/api/v1/nodes/${K8S_NODE_NAME}/status"
echo " * ${gpu_memory_value} of gpu memory added to ${K8S_NODE_NAME} (veriff.com/gpu-memory)"
sleep infinity
---
#
# this DaemonSet will run in all g4dn.xlarge nodes and patching them to add them gpu memory custom resources
#
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: add-gpu-memory
namespace: kube-system
spec:
selector:
matchLabels:
name: add-gpu-memory
template:
metadata:
labels:
name: add-gpu-memory
spec:
tolerations:
- key: "special"
operator: "Exists"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- g4dn.xlarge
serviceAccountName: add-gpu-memory
containers:
- name: add-gpu-memory
image: bitnami/kubectl
resources:
limits:
cpu: 40m
memory: 50M
requests:
cpu: 1m
memory: 1M
volumeMounts:
- mountPath: /app.sh
name: code
readOnly: true
subPath: app.sh
command:
- bash
- /app.sh
env:
#
# this variable is used in script to patch nodes to know what node he is running
#
- name: "K8S_NODE_NAME"
valueFrom:
fieldRef:
apiVersion: "v1"
fieldPath: "spec.nodeName"
priorityClassName: system-node-critical
volumes:
- name: code
configMap:
name: add-gpu-memory
#
# rbac permissions used by daemonset to patch nodes
#
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: add-gpu-memory
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: add-gpu-memory
namespace: kube-system
rules:
- apiGroups:
- "*"
resources:
- nodes
verbs:
- get
- list
- apiGroups:
- "*"
resources:
- nodes/status
verbs:
- patch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: add-gpu-memory
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: add-gpu-memory
subjects:
- kind: ServiceAccount
name: add-gpu-memory
namespace: kube-system
```
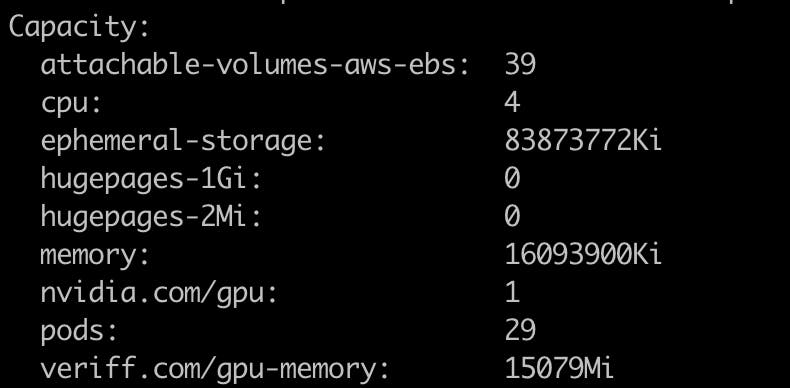
Se você verificar seu nó usando “kubectl describe node/NAME”, pode ver que ele possui o recurso veriff.com/gpu-memory disponível.
Agora que sabemos que nosso script de adição de memória GPU funciona, vamos aumentar nosso cluster para que tenhamos múltiplos nós de GPU disponíveis.
Para testá-lo, vamos modificar nossa implantação para usar este novo recurso.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-example
spec:
replicas: 6
selector:
matchLabels:
app: gpu-example
template:
metadata:
labels:
app: gpu-example
spec:
containers:
- name: gpu-example
image: eritikass/gpu-load-test
env:
# isso fará com que a aplicação cuda saiba usar qualquer GPU disponível
- name: NVIDIA_VISIBLE_DEVICES
value: all
resources:
requests:
veriff.com/gpu-memory: 104Mi
limits:
veriff.com/gpu-memory: 104Mi
```
```
Depois disso, é visível que os pods estão divididos entre os nós.

Com recursos regulares como CPU e memória, o Kubernetes saberá quanto os pods (contêineres) estão realmente usando e se alguém tentar usar mais – o Kubernetes irá restringir isso. No entanto, com nosso novo recurso personalizado, não há uma salvaguarda real no lugar que impeça algum pod “maléfico” de usar mais memória GPU do que a declarada. Portanto, você precisa ser muito cuidadoso ao definir os recursos ali. Quando os pods tentam usar mais memória GPU do que um nó tem disponível, isso geralmente resulta em algumas falhas muito feias.
Na Veriff, resolvemos esse problema com monitoramento e alerta extensivos para nosso novo uso de Recursos Personalizados de GPU. Também desenvolvemos ferramentas internamente para medir o uso de GPU de aplicações de ML sob carga.
Todos os exemplos de código deste post podem ser encontrados em https://github.com/Veriff/gpu-sharing-examples.